This post represents the first in a series of content we will be sharing to walk step-by-step through our data stack development process and provide some guidance to others facing the common problem of consolidating data from disparate locations to drive meaningful insights. Of course, there are a myriad of ways to solve any problem in data and there’s rarely a one size fits all solution; what follows is the stack and implementation process we chose for our particular project with context on why we built it the way that we did. As always, if you have any thoughts or questions — please feel free to let us know in the comments below!
At South Shore Analytics, we are passionate about the work we do for our clients – whether it be full data stack implementations, specific dashboard development, data pipeline set-up, or some combination of all of the above. As you can imagine, though, it is challenging for us to showcase our work given almost all of the datasets we work with are proprietary and highly confidential to our clients! So, we wanted to build a case study with publicly accessible data to show the world why we love doing this type of work and share a few of our tips and tricks.
For our case study, we’ve decided to build a deeply interactive series of dashboards with detailed information on the National Hockey League (NHL). We’re big sports fans, and the NHL provides a vast amount of data to work with on a subject matter that is easy to engage with. That said, the concepts we’ve applied to building a well architected data stack and dashboard solution for the NHL can just as easily be applied to helping your business generating deep marketing campaign insights, evaluate key trends in your financials on a monthly basis, or identify the key elements holding back your business’s operations from reaching that next level of efficiency.
Without further ado, let’s dive into how we configured the data stack for this particular project.
Step 0: Start With The End In Mind
If you’ve ever spent much time working with Data, you know that ‘Configuring your Data Stack’ can be an intimidating thing to discuss. Today, there are dozens of high quality software options on the market — each of which with a specific set of capabilities and strengths. As a result, it can be near impossible to keep track of all the pieces of the “Modern Data Stack”, let alone to feel well informed enough to make decisions on what is best for your business or specific use case.
The very first step in the process is to take some time to think about what you want to be able to build and report on. Too often, a business will just decide that they want to ‘do analytics’ without getting clear about what metrics are most important to them and what types of information they specifically want to be able to analyze and report on. While there are some data pipeline development and data modeling principles that will remain largely unchanged regardless of what you want to ultimately build in a dashboard, it is still important to start thinking about what you want to be able to report on and how you want to be able to slice and dice the data.
Planning ahead will save you the pain of realizing 2 or 3 months down the line that you don’t have all of the data you need, or that you spent time modeling the data in a way that doesn’t fully allow you to answer the key questions you have about your business or project.
Step 1: Understand Your Data Sources And Where They Come From
Before jumping in to choosing and configuring the technical elements of your data stack, it is first important to understand the raw data you are going to be working with. Start by asking some basic questions like:
- How many individual sources will I need to work with?
- How popular are these sources — is it likely that many others have connected to them before?
- How frequently is each data source updated? How frequently do I *need* the ingested data to be updated?
- How can I access the raw data from each of these sources? Can I access them from an API? An SFTP folder? A manually updated Google Sheet?
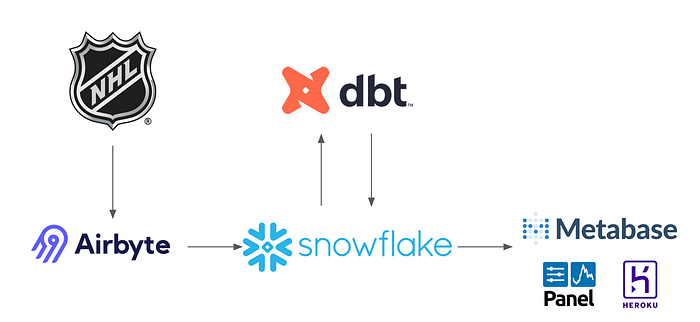
For the purposes of this project, we’re using one primary source (the NHL API) which likely isn’t incredibly popular, but which is openly accessible via API. This means we will need to employ some custom solutions to access the data, but we don’t need to worry about things like storing and handling individual file exports.
Step 2: Selecting Your Cloud Data Storage Solution
Once you understand the needs dictated by your set of Data Sources, choosing the appropriate cloud data storage solution is an important next step. While we’ve worked (and had great experiences) with most of the large cloud data warehouse platforms on the market, for this project we elected to utilize Snowflake. We knew that while our Data Source was small to start, it had the potential to grow and evolve over time. One of the key benefits of Snowflake is that it separates compute and storage across the platform — allowing the user to scale each facet as needed to best optimize the performance of the data warehouse while balancing cost throughout. Additionally, Snowflake is easy to use while also integrating neatly across multiple cloud platforms, allowing for flexibility and scalability as a project expands.

Step 3: Configuring the Pipeline
Once you’ve set up a data warehouse, the next step is to build the data pipeline between your data source and warehouse. One option to do this is to utilize one of the major data integration tools — such as Airbyte, Fivetran or Stitch, which provide out-of-the-box connectors with automatic updates and self management — ideal for teams that don’t want to micro manage infrastructure. If the source you’re working with is a bit more niche, however, the solution you apply here will likely need to be a bit more bespoke. In our case we elected to use Airbyte, which, similar to Fivetran and Stitch, provides a suite of industry-standard, pre-built connectors. However, it also allows for easy, open-source development and management of custom connectors. For our project, Airbyte’s customizability with an ETL focus allowed us to best manage our data pipeline while also controlling costs thanks to allowing us to use incremental (instead of full refresh) data updates. Some users will find it easier or necessary to use an orchestration tool like Dagster or Apache Airflow to use Python to develop their data pipelines with an ability to explicitly or implicitly define dependencies between assets in their pipeline; we love these tools and use them for some of our clients, but they were not necessary for a project of our size with a singular source of data.

Step 4: Transforming and Structuring your Data
Once you have connected and loaded data into your data warehouse, the next step is to clean, transform, and validate your data. Selecting the right data transformation tool for this job is fully dependent on the type of data you have, since a No-SQL data transformation tool will not work for a tabular database. The tool we elected to employ here, dbt, has modular SQL developmental focus and provides extensive testing, validation, and documentation capabilities to ensure data integrity and simplify development in a version controlled environment — making it the perfect fit for our data stack. However, for workflows that require pre-loading and cross-warehouse transformations, alternatives such as Apache Airflow or Luigi might be better options.

Step 5: Data Visualization
Once you have been able to extract, transform, and load your data into the data warehouse, you next need to decide the best way to visualize and deploy your final data product. Business Intelligence (BI) tools such as Tableau, Power BI, and Looker provide similar value propositions regarding advanced visualization and SQL integration for large projects and enterprises. However, medium-sized data ecosystems with extensive ETL workflows (like ours) are more suited to a straightforward BI tool focused on collaboration and sharing of detailed dashboards, such as Metabase. Its user-friendly interface, vast visualization library, and embedding capabilities make developing sleek and detailed visualizations and dashboards straightforward and easy to deploy. For more advanced users, Metabase allows some SQL integration for direct access to the data before visualization since the platform doesn’t have direct ETL capabilities built-in.

With any BI tool, there are sometimes constraints to consider when developing visualizations. For projects that require unique / proprietary analytical graphs, such as ours, it might be necessary to develop a few visualizations outside of a BI tool altogether. We elected to use Panel, an open source Python library, to build a second facet of our interactive dashboard. Compared to other Python libraries, Panel is extremely flexible, extensible, and easy-to-use to integrate any visualizations into a neat, interactive dashboard. To fully bring this web app to life, we used Heroku for deployment due to its straight-forward Git based workflow and built-in infrastructure management. For larger and more complex projects that require direct infrastructure management, deploying via Azure, Google Cloud, and AWS alternatives may cut costs and better suit the project depending on your needs.

Conclusion
When it comes to data (or truly, almost anything in life) there is rarely such a thing as a perfect, one-size-fits-all solution. That said, the products we walked through above have served us incredibly well at South Shore and we’re confident they will be great additions to your new Data Stack! If you have any additional thoughts, questions, or suggestions — please let us know in the comments below.
About Us: We are a Data Consulting Firm based out of Chicago, specializing in full stack data implementation. We’re skilled in Big Data , data modeling, and visualization.